CuKee
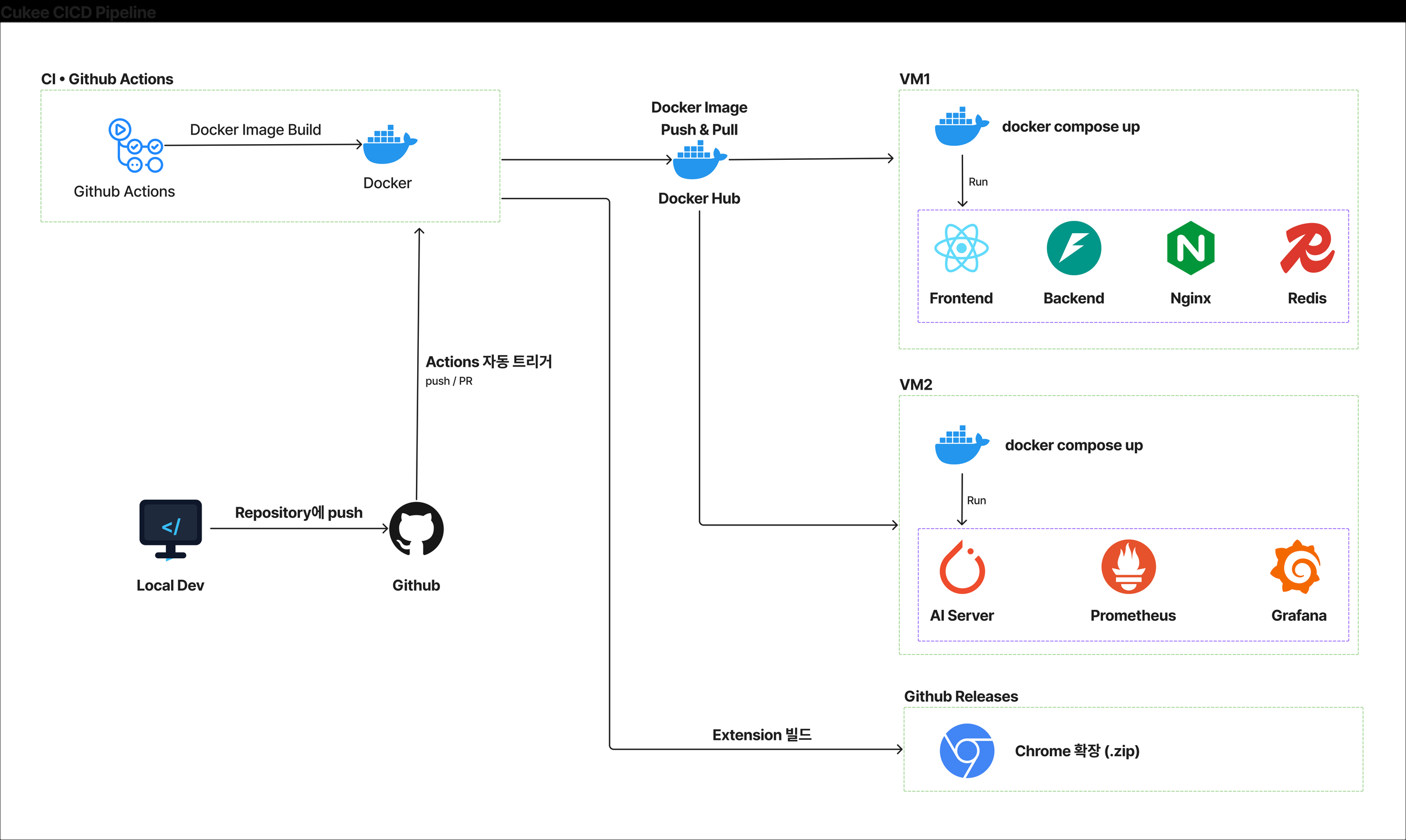
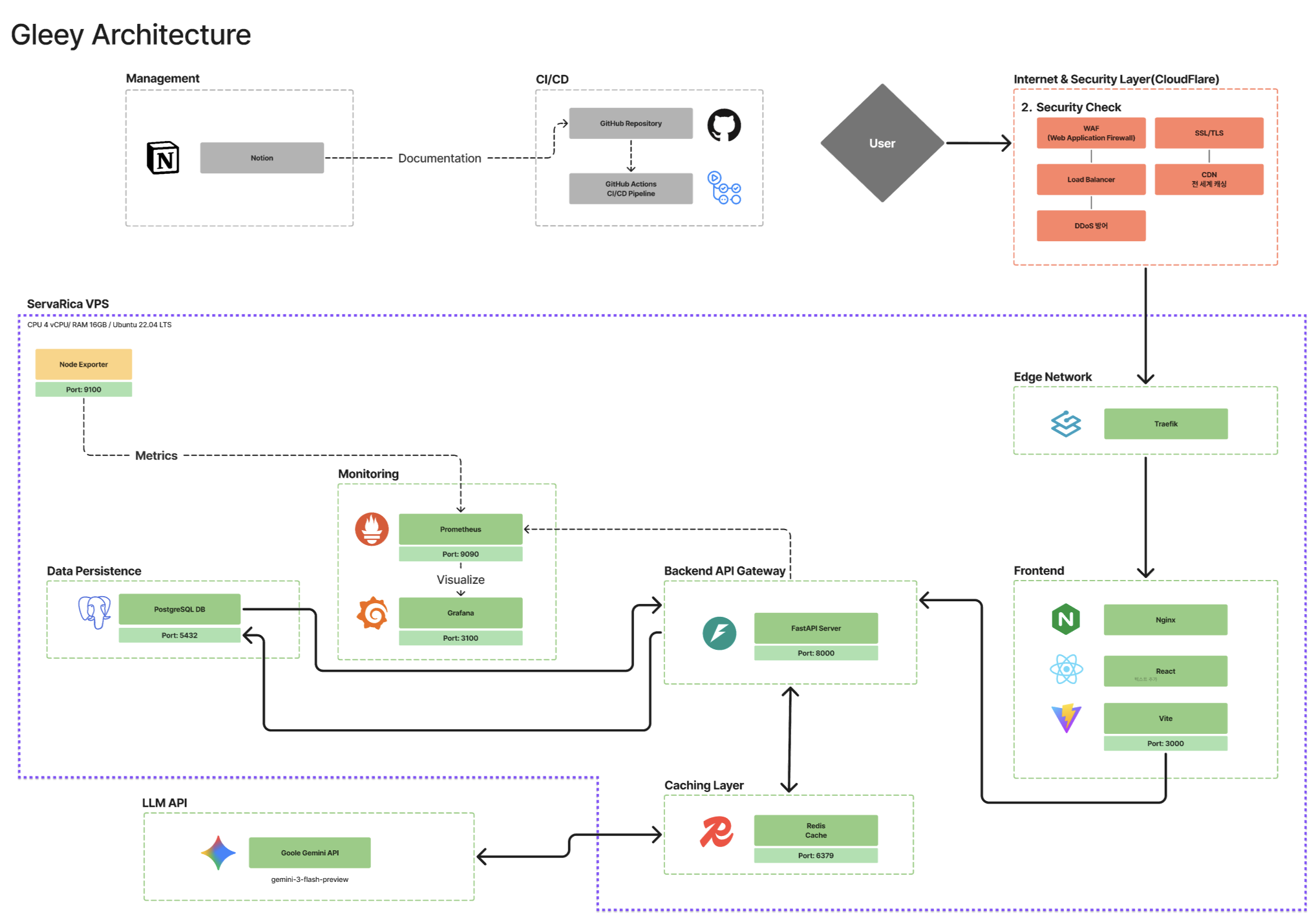
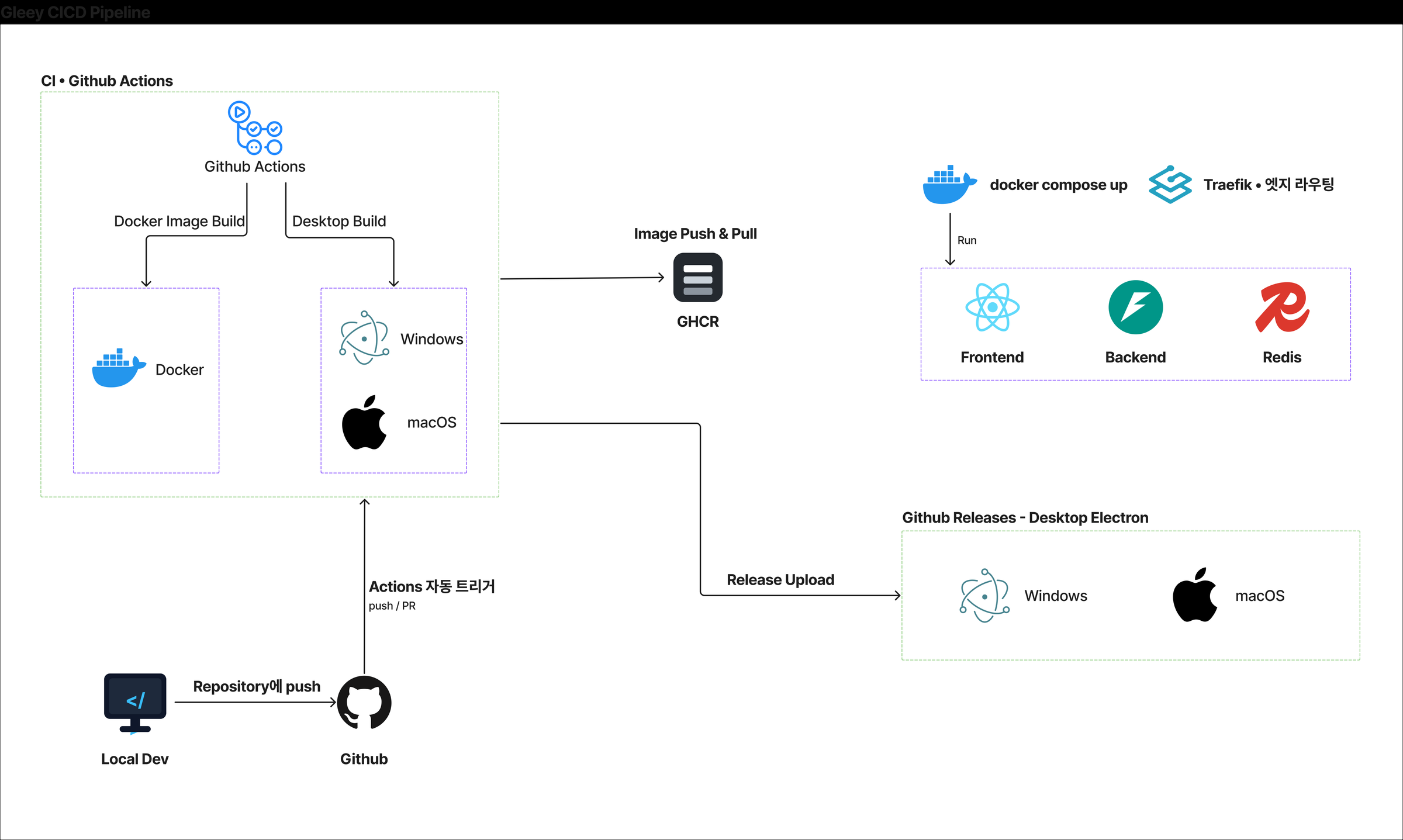
인프라 아키텍처 — 2-Tier 구성과 판단 근거
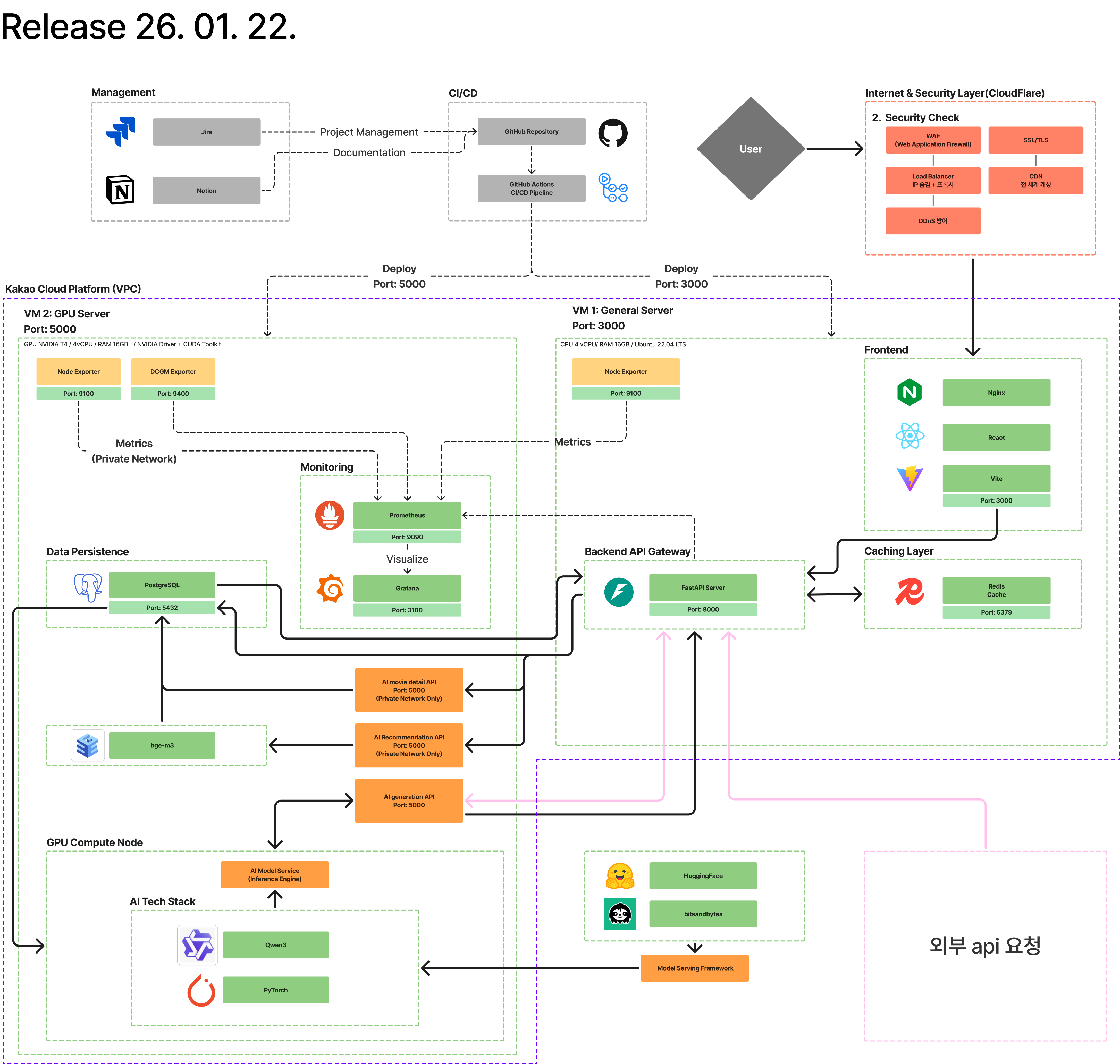
왜 DB를 GPU 서버에 배치했는가
상황
VM1에 배정된 저장 용량은 10GB. Frontend, Backend, Nginx, Redis 컨테이너만으로도 저장 공간이 부족한 상황이었습니다.
판단
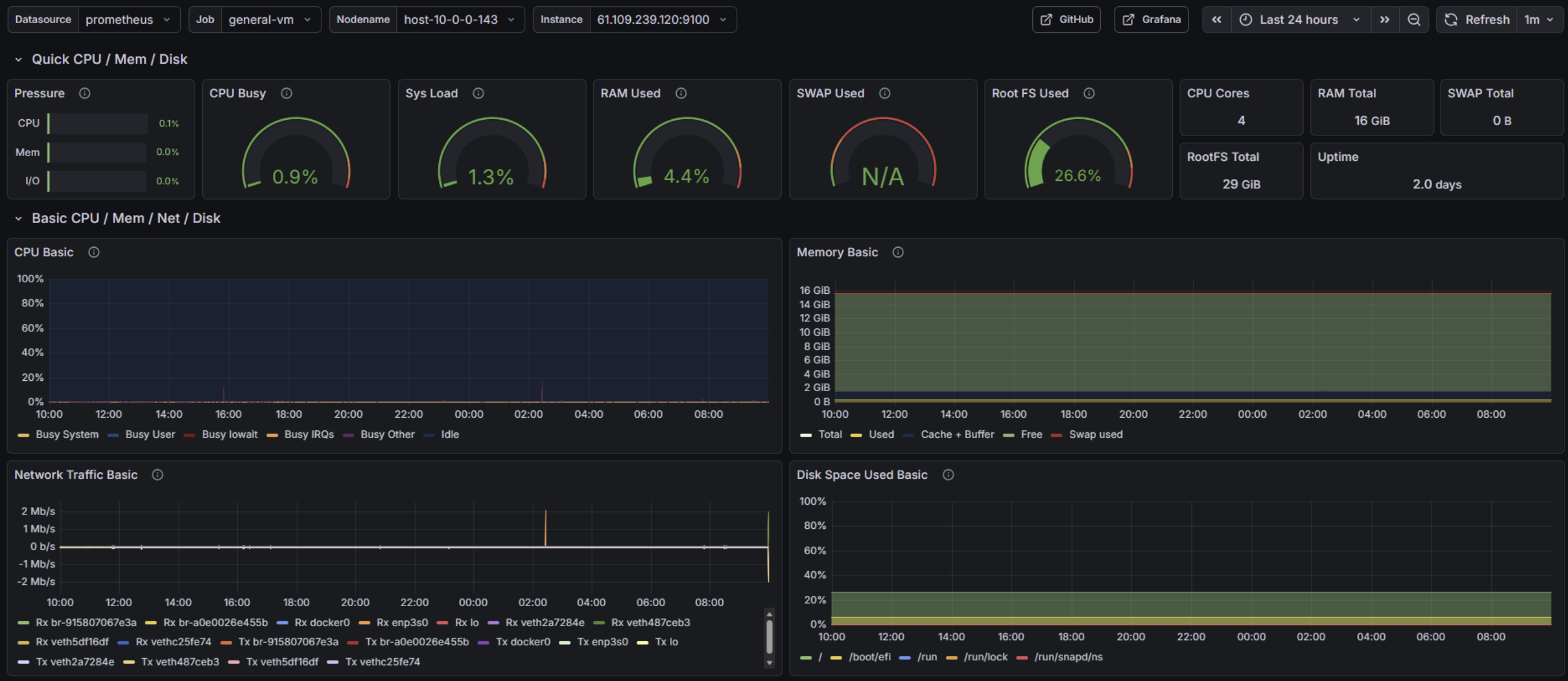
VM2(GPU 서버)는 100GB가 배정되어 있고, AI 모델은 메모리에 로드되므로 디스크 여유가 충분했습니다. PostgreSQL을 GPU 서버에 설치하고, VM1에서만 접속할 수 있도록 네트워크를 격리하여 보안을 확보했습니다.
결과
애플리케이션과 DB 사이의 네트워크 경로가 명확해졌고, GPU 서버의 남는 디스크를 활용하여 별도 스토리지 없이 안정적으로 운영할 수 있었습니다.